Parallel Reinsertion for Bounding Volume Hierarchy Optimization
Computer Graphics Forum (Proceedings of Eurographics 2018) 37(2):463-473, 2018
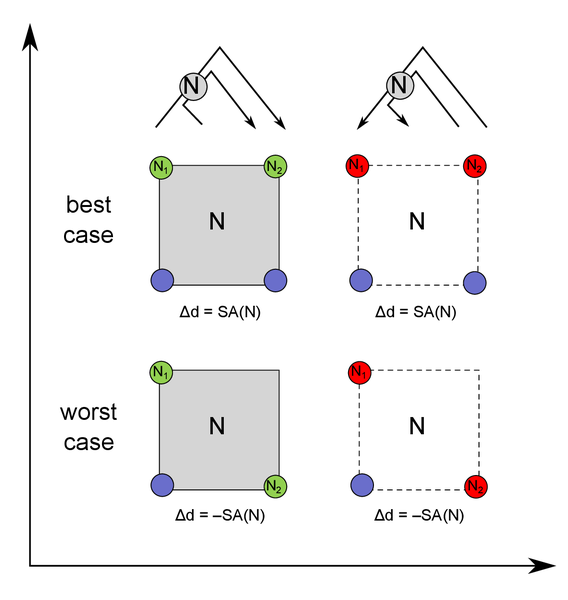
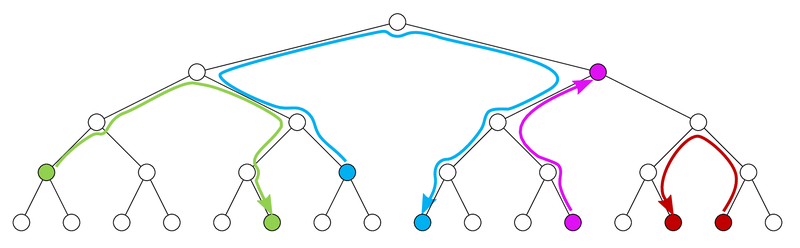
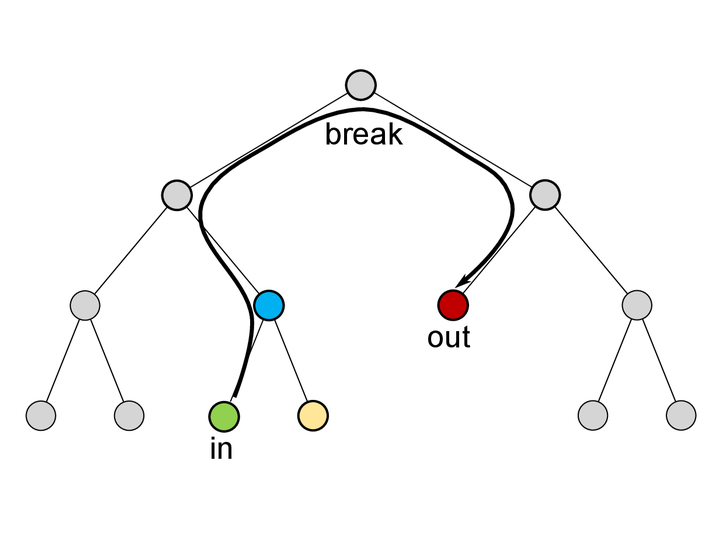
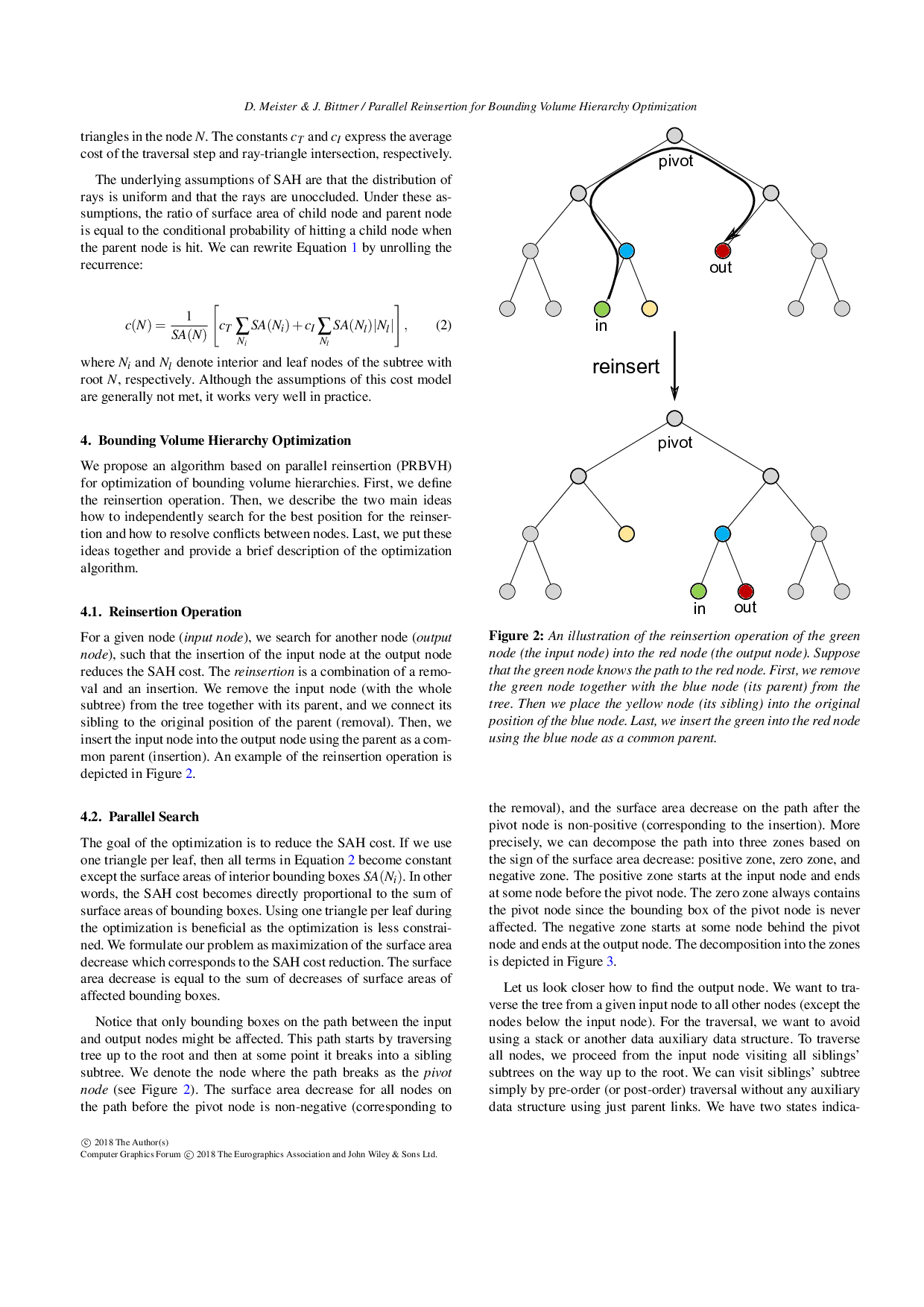
We present a novel highly parallel method for optimization of bounding volume hierarchies (BVH) targeting contemporary GPU architectures. The core of our method is based on the insertion-based BVH optimization that is known to achieve excellent results in terms of the SAH cost. The original algorithm is, however, inherently sequential: no efficient parallel version of the method exists which limits its practical utility. We reformulate the algorithm while exploiting the observation that there is no need to remove the nodes from the BVH prior to finding their optimized positions in the tree. We can search for the optimized positions for all nodes in parallel while simultaneously tracking the corresponding SAH cost reduction. We update in parallel all nodes for which better position was found while efficiently handling potential conflicts during these updates. We implemented our algorithm in CUDA and evaluated the resulting BVH in the context of the GPU ray tracing. The results indicate that the method is able to achieve the best ray traversal performance among the state of the art GPU-based BVH construction methods.
Ukázky







Obrázky