Clustering and visualization of tabular data with nominal attributes
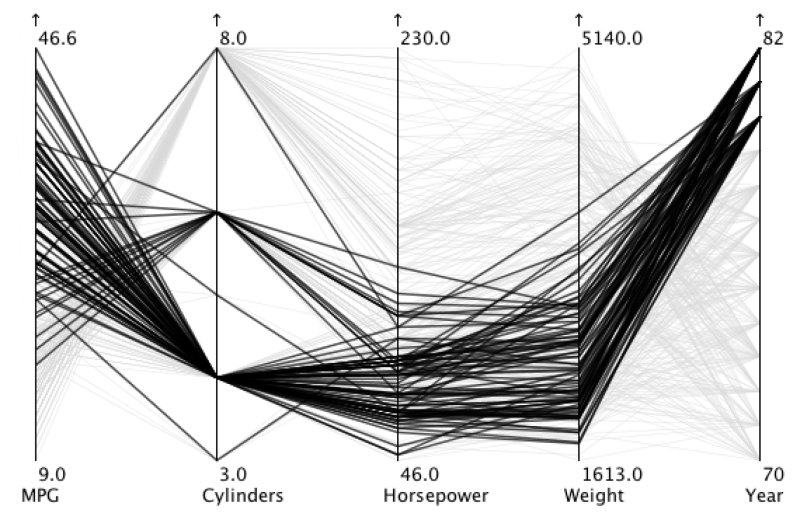
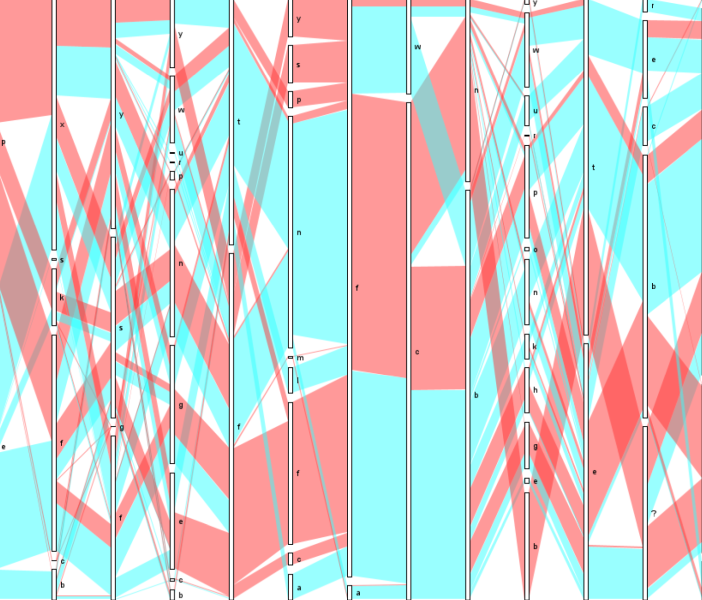
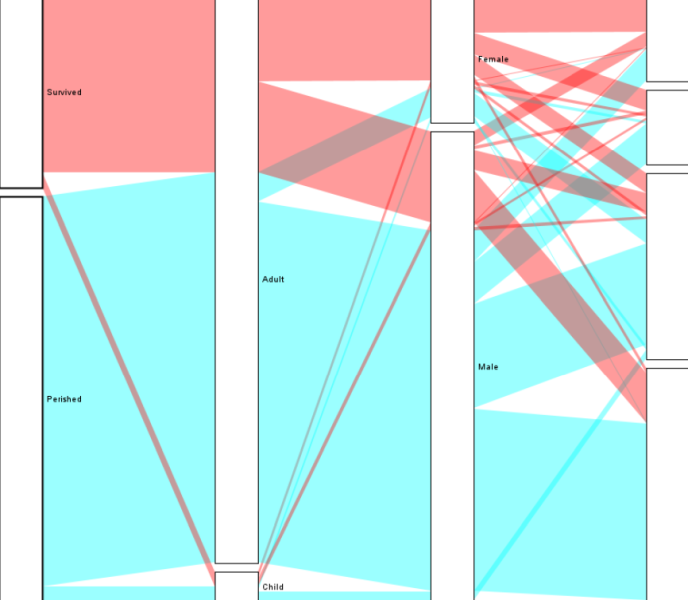
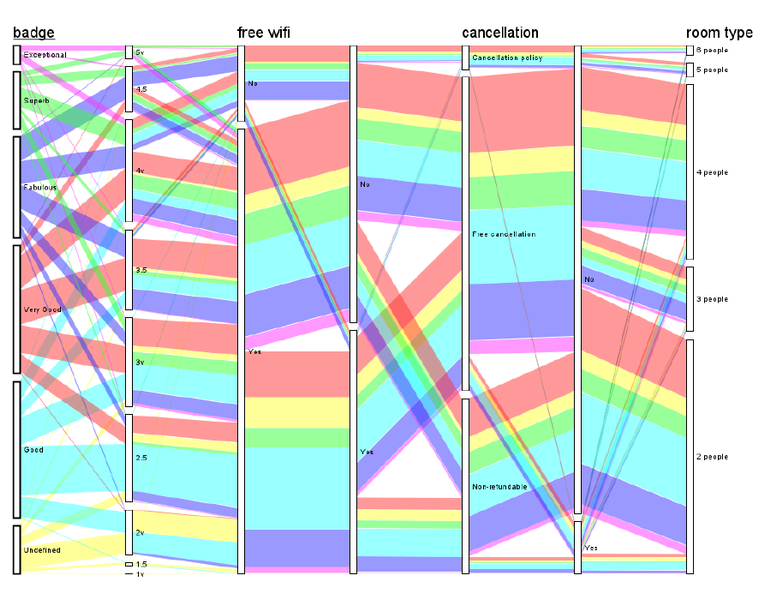
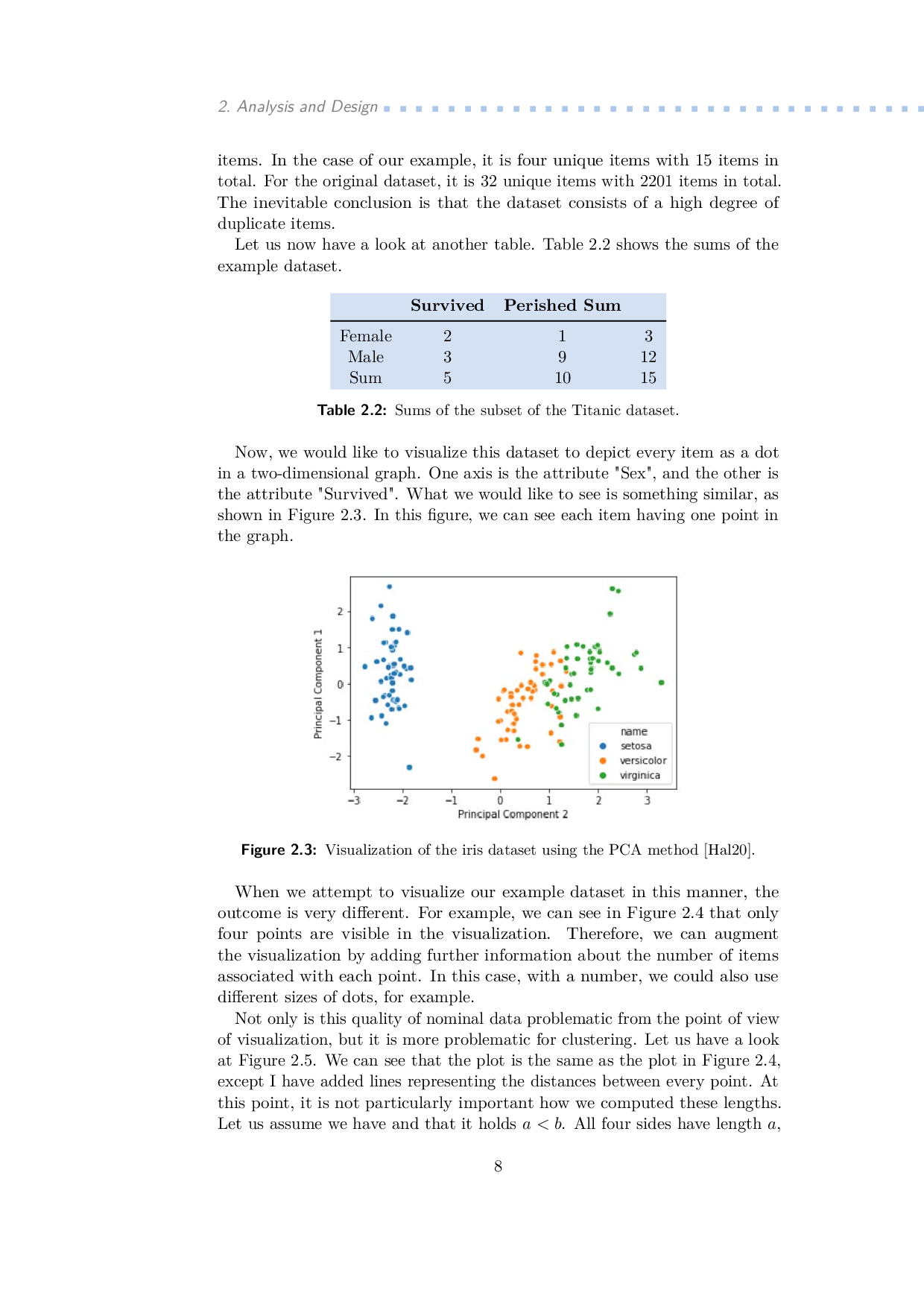
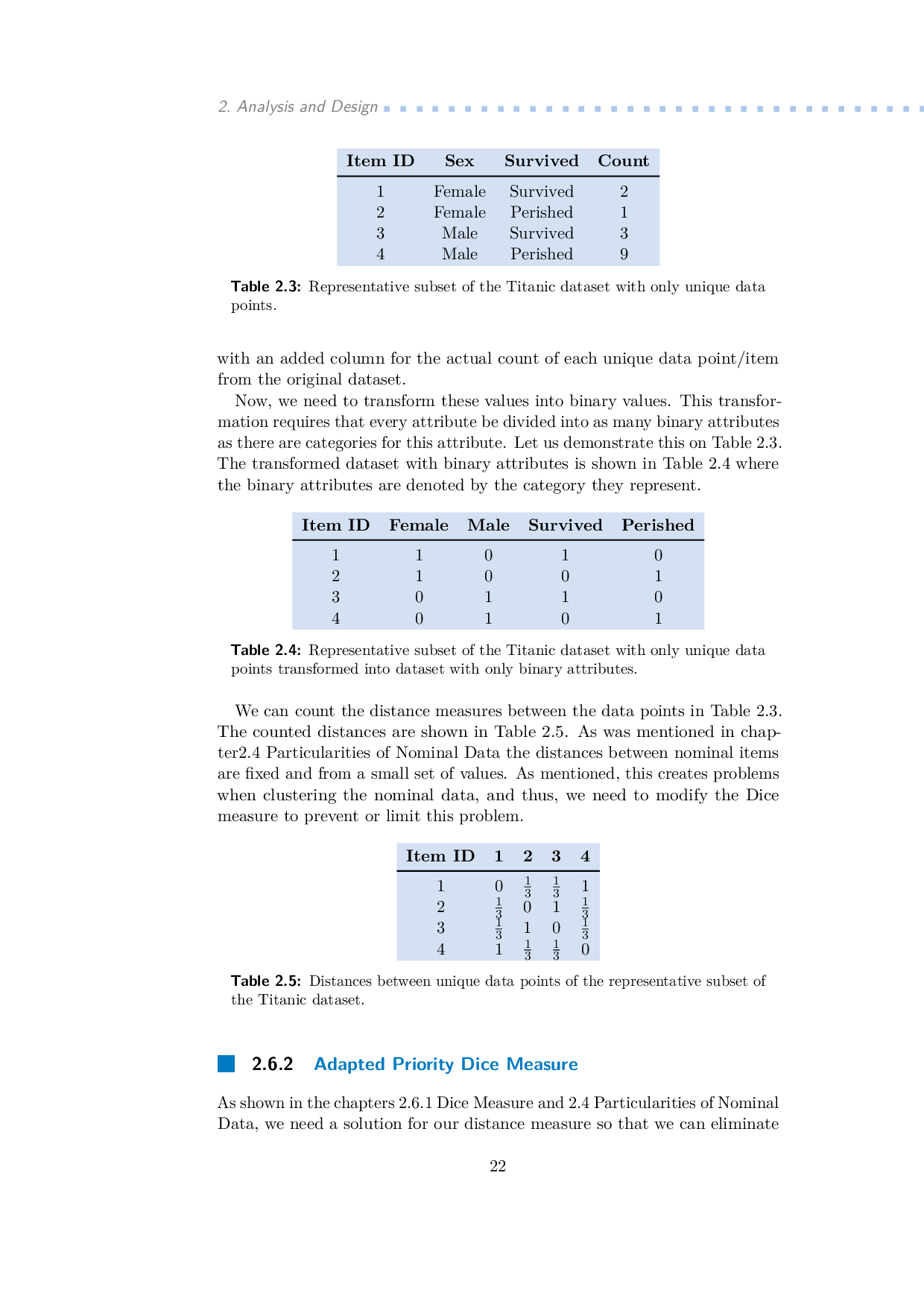
This master's thesis discusses the different approaches to the clustering and subsequent visualization of nominal and ordinal data. As such, it explains the tabular dataset, defines attribute types, and outlines its visualization task. It explains the several clustering methods (hierarchical clustering, k-means, k-modes, parallelogram clustering) for clustering nominal data and the Dice similarity measure for counting distance. It also contains the description of the used algorithm - parallelogram clustering. Finally, it shows how the algorithm was implemented into the XDat tool and subsequently shows the experimental results of four additional datasets.
Samples




Images