Shlukování a vizualizace tabulkových dat s nominálními atributy
Tato diplomová práce se zabývá různými přístupy ke clusterování a následné vizualizaci nominálních a ordinálních dat. Ukazuje tabulkové datasety, definuje typy attributů a popisuje úkoly pro vizualizaci. Dále vysvětluje různé clusterovací metody (hierarchické clusterování, k-means, k-modes, paralellogramové cluserování) pro clusterování nominálních dat. K výpočtu vzdálenosti je vystvěleno Dicova míra podobnosti. Ukazuje jakým způsobem byl implementován použitý algoritmus parallelogramového clusterování v nástroji XDat. Výsledky jsou prezentovány na čtyř datasetech.
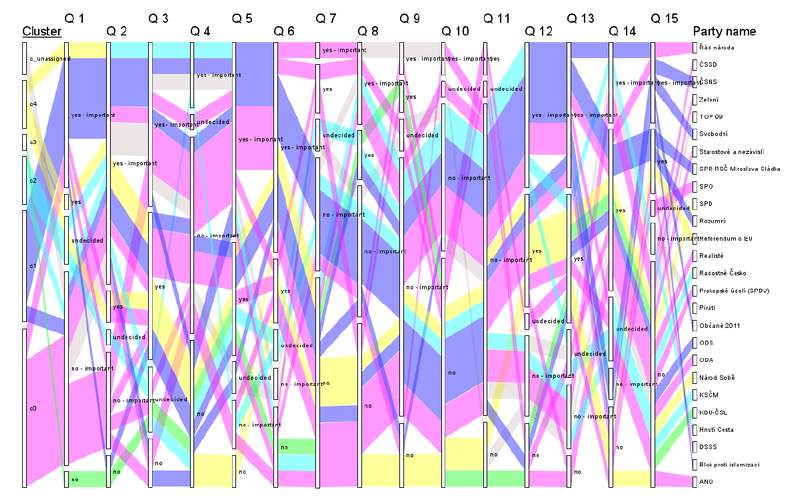
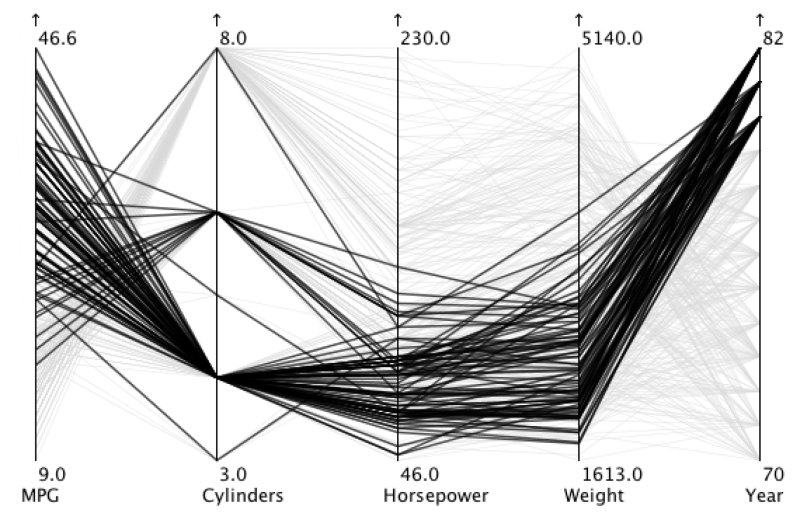
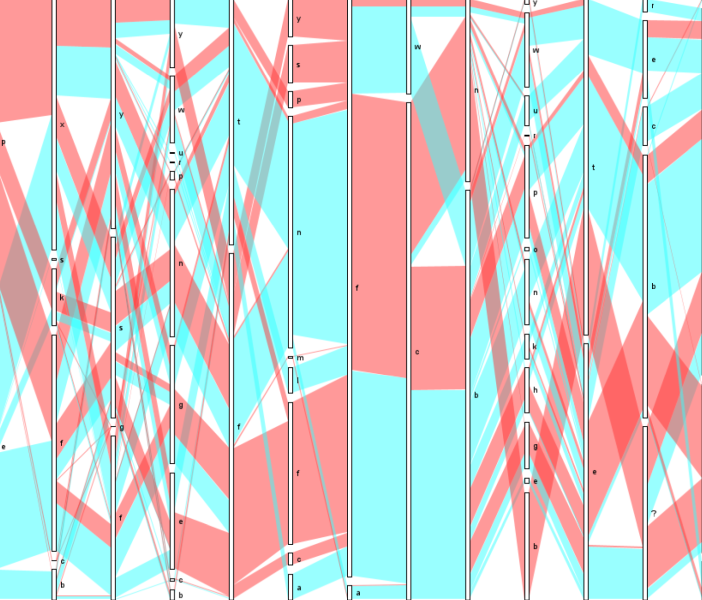
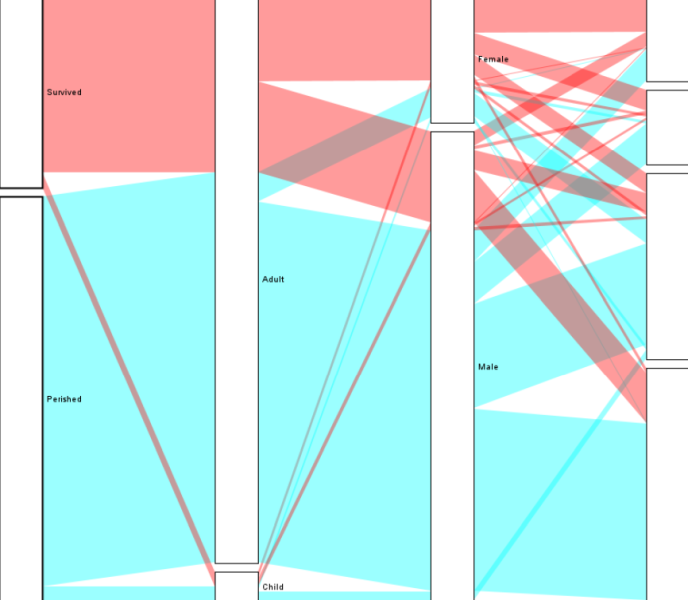
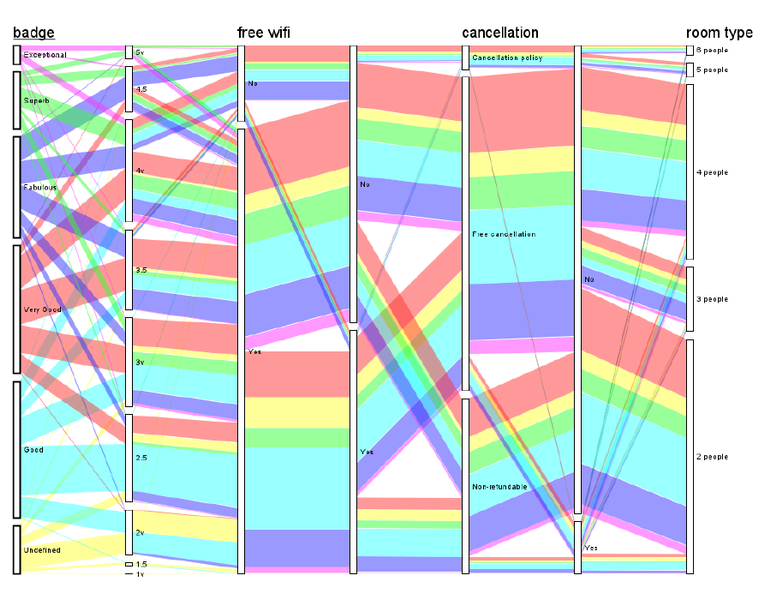
Ukázky

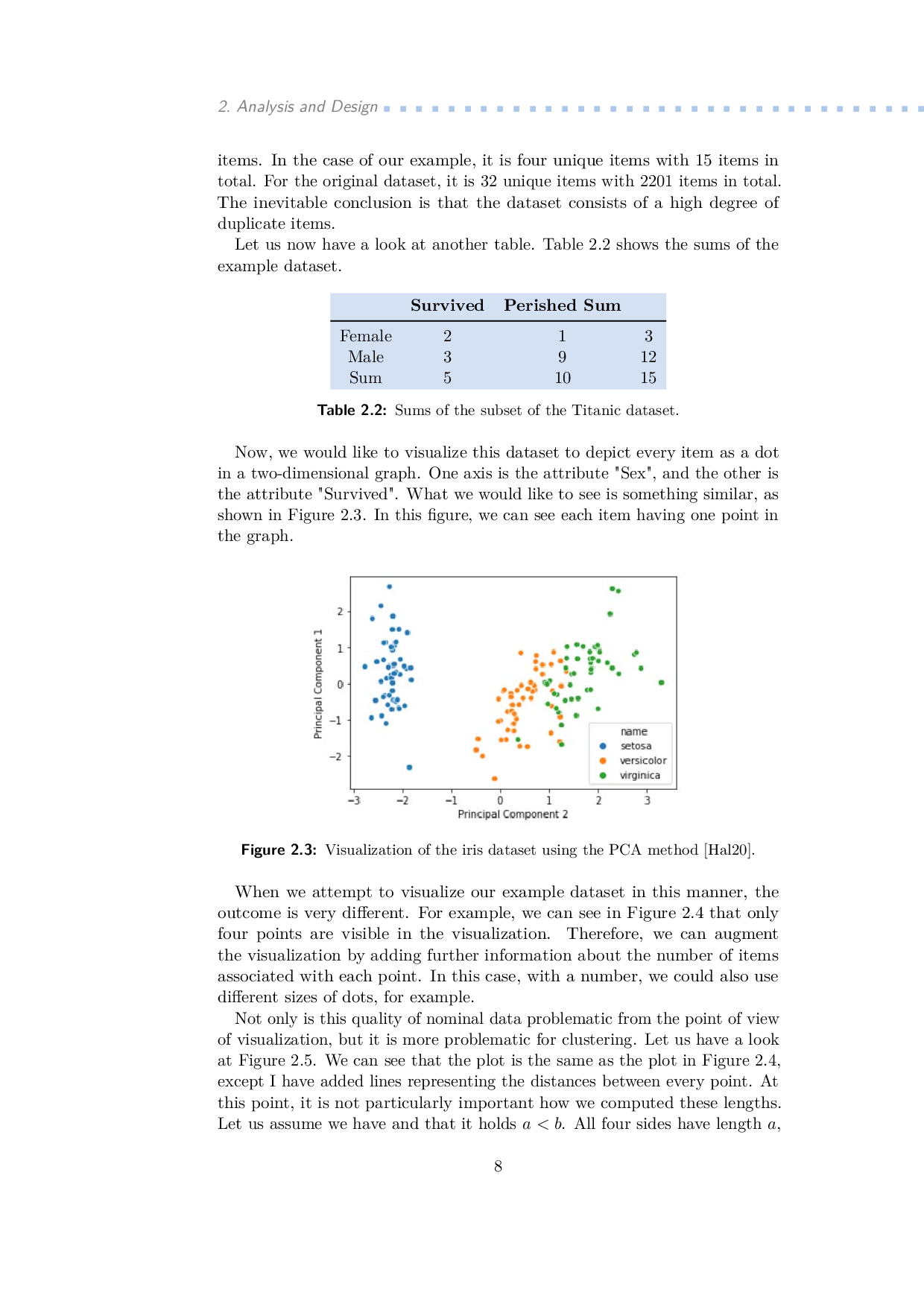


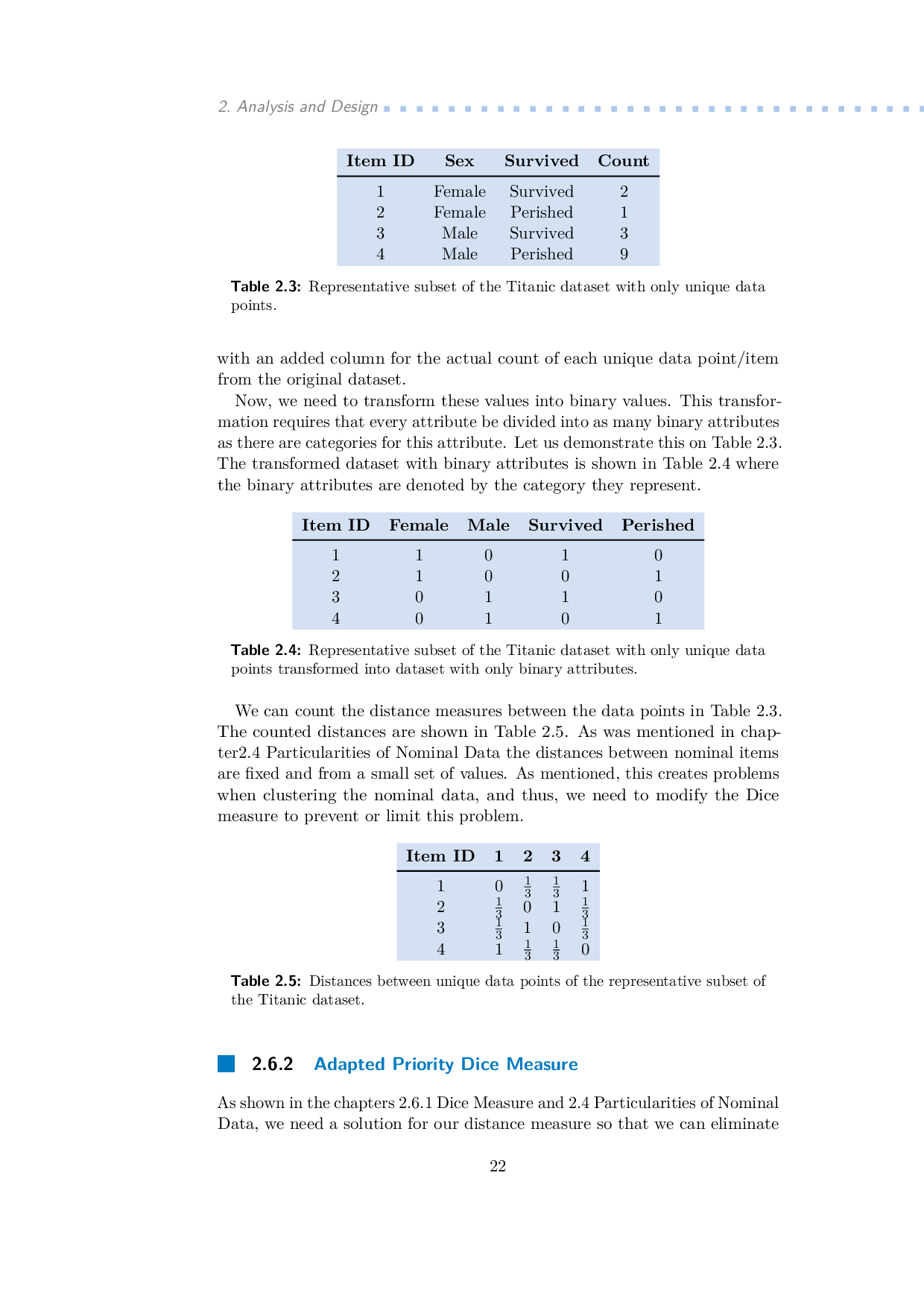

Obrázky